1. Einführung
1.1. Was ist Agentisches Programmieren?
Agentisches Programmieren (Agentic Coding) beschreibt einen Paradigmenwechsel in der Softwareentwicklung: Statt passiver Code-Vervollständigung arbeiten KI-Assistenten als autonome Agenten, die eigenständig Code erkunden, editieren und erklären – über das gesamte Projekt hinweg.
Im Gegensatz zu klassischen Autocomplete-Tools können agentische Coding-Assistenten:
-
Projektstrukturen analysieren und verstehen
-
Mehrstufige Aufgaben selbstständig planen und ausführen
-
Dateien erstellen, bearbeiten und löschen
-
Terminal-Befehle ausführen
-
Auf Fehler reagieren und iterativ verbessern
1.2. Verfügbare Tools
| Tool | Anbieter | Besonderheiten |
|---|---|---|
Claude Code |
Anthropic |
Terminal-basiert, tiefe Codebase-Integration |
GitHub Copilot |
GitHub/Microsoft |
IDE-Integration, unterstützt mehrere LLMs (inkl. Claude, GPT-4, Gemini) |
Cursor |
Cursor Inc. |
VS Code Fork mit nativer KI-Integration |
Cody |
Sourcegraph |
Codebase-weite Suche und Kontext |
Gemini Code Assist |
Integration in Google Cloud |
|
ChatGPT + Code Interpreter |
OpenAI |
Web-basiert mit Code-Ausführung |
Mistral + Continue |
Mistral AI |
Open-Source-freundlich, selbst hostbar |
1.3. Über dieses Tutorial
Dieser Leitfaden verwendet Claude Code als Referenz-Tool, da es aktuell eines der leistungsfähigsten agentischen Coding-Tools ist. Die beschriebenen Prinzipien und Workflows sind jedoch übertragbar:
|
Übertragbarkeit auf andere Tools:
|
1.4. Warum AsciiDoc statt Markdown?
Claude Code verwendet standardmäßig Markdown-Dateien (CLAUDE.md, AGENTS.md). Dieses Tutorial nutzt bewusst AsciiDoc (.adoc), da es für technische Dokumentation mächtiger ist:
| Feature | Markdown | AsciiDoc |
|---|---|---|
Tabellen |
Einfach |
Komplex mit Colspan, Formatierung |
Includes |
❌ |
|
Admonitions (NOTE, TIP, WARNING) |
Nicht standard |
✅ Nativ |
Inhaltsverzeichnis |
Tool-abhängig |
|
Querverweise |
Manuell |
|
Diagramme |
Extern |
PlantUML, Mermaid integriert |
Collapsible Sections |
❌ |
|
PDF/DocBook Export |
Begrenzt |
✅ Professionell |
|
KI-Assistenten verstehen AsciiDoc problemlos. Die Syntax ist Markdown ähnlich genug, dass Claude, GPT und andere Modelle Falls dein Tool nur |
Der Kern dieses Tutorials – die Trennung von fachlicher Spezifikation (WAS) und technischer Implementierung (WIE) – ist toolunabhängig und verbessert die Ergebnisse mit jedem KI-Assistenten.
2. Installation von Claude Code
2.1. macOS (mit Homebrew)
2.1.1. Variante 1: Native Installer (empfohlen)
Der native Installer benötigt kein Node.js und aktualisiert sich automatisch:
curl -fsSL https://claude.ai/install.sh | bashNach der Installation ein neues Terminal-Fenster öffnen, dann:
claude --version2.1.2. Variante 2: Homebrew Cask
brew install --cask claude-code
claude --version
Homebrew-Installationen aktualisieren sich nicht automatisch. Regelmäßig brew upgrade claude-code ausführen.
|
2.1.3. Variante 3: npm (falls Node.js bevorzugt wird)
Voraussetzung: Node.js 18+
# Falls Node.js fehlt
brew install node
# Claude Code installieren
npm install -g @anthropic-ai/claude-code
# Bei "command not found":
echo 'export PATH="$(npm config get prefix)/bin:$PATH"' >> ~/.zshrc
source ~/.zshrc
claude --version2.2. Linux
2.2.1. Variante 1: Native Installer (empfohlen)
curl -fsSL https://claude.ai/install.sh | bashFalls command not found erscheint:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc2.2.3. Variante 3: npm
# npm-Verzeichnis ohne sudo einrichten
mkdir ~/.npm-global
npm config set prefix '~/.npm-global'
echo 'export PATH=~/.npm-global/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
# Installation
npm install -g @anthropic-ai/claude-code
claude --version
Niemals sudo npm install -g verwenden – das verursacht Berechtigungsprobleme.
|
2.3. Windows
2.3.1. Variante 1: PowerShell (Native Installer)
irm https://claude.ai/install.ps1 | iex
claude --version2.3.2. Variante 2: CMD
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd2.3.3. Variante 3: WSL (Windows Subsystem for Linux)
WSL 1 und WSL 2 werden unterstützt. Nach WSL-Setup die Linux-Anweisungen befolgen.
2.3.4. Variante 4: Git Bash
Zuerst Git for Windows installieren, dann:
curl -fsSL https://claude.ai/install.sh | bash3. Der strukturierte Workflow
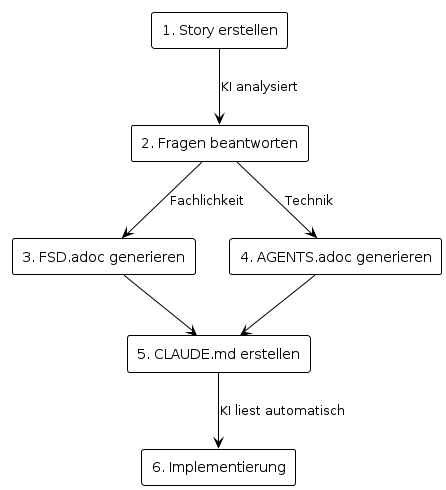
3.1. Schritt 1: Story erstellen
Die story.adoc ist der Ausgangspunkt – eine grobe Skizze der Aufgabenstellung mit technischen Rahmenbedingungen.
3.1.2. story.adoc erstellen
= Story: [Projektname]
:revdate: 2026-03-19
== Vision
[2-3 Sätze: Was soll das System leisten? Welches Problem löst es?]
== Grobe Anforderungen
* [Anforderung 1]
* [Anforderung 2]
* [Anforderung 3]
== Technische Rahmenbedingungen
[cols="1,2"]
|===
| Aspekt | Vorgabe
| Sprache
| Java 21
| Build-Tool
| Maven / Gradle
| Framework
| Spring Boot 3.x / Quarkus / ...
| Datenbank
| PostgreSQL / MongoDB / ...
| Architektur
| Hexagonale Architektur / Clean Architecture / ...
| Design Patterns
| Repository, Factory, Strategy, ...
| Dokumentation
| AsciiDoc (.adoc)
| Tests
| JUnit 5, AssertJ, Testcontainers
|===
== Offene Fragen
* [Was ist noch unklar?]
* [Welche Entscheidungen stehen aus?]
== Nicht-Ziele (Out of Scope)
* [Was gehört explizit NICHT zum Projekt?]3.1.3. Beispiel: Bestellsystem
= Story: Online-Bestellsystem
== Vision
Ein Bestellsystem für einen mittelständischen Händler, das Kunden
ermöglicht, Produkte online zu bestellen und den Bestellstatus
zu verfolgen.
== Grobe Anforderungen
* Kunden können Produkte in einen Warenkorb legen
* Bestellungen werden mit Zahlungsart erfasst
* Sachbearbeiter können Bestellungen einsehen und bearbeiten
* E-Mail-Benachrichtigung bei Statusänderungen
== Technische Rahmenbedingungen
[cols="1,2"]
|===
| Aspekt | Vorgabe
| Sprache | Java 21
| Build-Tool | Gradle (Kotlin DSL)
| Framework | Spring Boot 3.3
| Datenbank | PostgreSQL 16
| Architektur | Hexagonale Architektur
| API | REST mit OpenAPI 3.0
| Dokumentation | AsciiDoc
| Tests | JUnit 5, AssertJ, Testcontainers
|===
== Offene Fragen
* Wie soll die Zahlungsabwicklung erfolgen?
* Gibt es ein bestehendes Kundensystem zur Integration?
== Nicht-Ziele
* Mobile App (nur Web)
* Internationalisierung (nur DACH-Region)3.2. Schritt 2: Claude Code starten und Fragen beantworten
Starte Claude Code im Projektverzeichnis:
cd mein-projekt
claude3.2.1. Initialer Prompt
Lies bitte specs/story.adoc und analysiere die Anforderungen.
Stelle mir gezielte Fragen, um:
1. Die fachlichen Anforderungen vollständig zu verstehen
2. Alle Unklarheiten zu beseitigen
3. Die technischen Entscheidungen zu validieren
Formatiere deine Fragen strukturiert nach Kategorien.
Frage NICHT nach Code oder Implementierungsdetails –
das kommt später.3.2.2. Typische Fragen von Claude
Claude wird Fragen stellen wie:
-
Welche Benutzerrollen gibt es?
-
Was passiert bei Stornierung einer Bestellung?
-
Gibt es Rabattsysteme oder Gutscheine?
-
Wie werden Retouren behandelt?
-
Soll die API versioniert werden?
-
Welche Authentifizierung (JWT, OAuth2, …)?
-
Gibt es Performance-Anforderungen (Requests/Sekunde)?
-
Soll Event Sourcing verwendet werden?
-
Was genau bedeutet "Bestellstatus verfolgen"?
-
Wer darf Bestellungen stornieren?
-
Wie lange werden Daten aufbewahrt?
| Beantworte die Fragen ausführlich. Je mehr Kontext Claude hat, desto besser werden die generierten Spezifikationen. |
3.3. Schritt 3: FSD.adoc generieren lassen
Nach dem Frage-Antwort-Dialog:
Erstelle basierend auf unserer Diskussion eine vollständige
fachliche Spezifikation als specs/fsd.adoc.
Verwende folgende Struktur:
- Glossar mit Ubiquitous Language
- Akteure und ihre Berechtigungen
- Anwendungsfälle (Use Cases) mit Vor-/Nachbedingungen
- Geschäftsregeln mit IDs
- Fachliches Datenmodell (ohne technische Details)
- Akzeptanzkriterien
Die Spezifikation soll von Fachexperten lesbar sein –
keine technischen Implementierungsdetails.3.3.1. Erwartete Struktur der fsd.adoc
Die fachliche Spezifikation verwendet User Stories als primäres Format – passend für Scrum-basierte Entwicklung an HTLs und in agilen Teams.
= Functional Specification: [Projektname]
:author: Fachbereich
:revdate: 2026-03-19
:toc: left
:sectnums:
== Einleitung
=== Zweck
[Geschäftlicher Kontext]
=== Scope
[Was ist enthalten, was nicht]
== Glossar
[cols="1,3"]
|===
| Begriff | Definition
| Bestellung
| Ein Auftrag eines Kunden über ein oder mehrere Produkte...
| Bestellposition
| Einzelne Zeile einer Bestellung mit Produkt, Menge, Preis
|===
== Akteure / Rollen
=== Kunde
* Kann Produkte suchen und bestellen
* Kann eigene Bestellungen einsehen
=== Sachbearbeiter
* Kann alle Bestellungen einsehen
* Kann Bestellstatus ändern
== Epics und User Stories
=== Epic: Bestellprozess
==== US-001: Bestellung aufgeben
[horizontal]
Story:: Als *Kunde* möchte ich *meinen Warenkorb bestellen können*,
damit *ich die gewünschten Produkte erhalte*.
Priorität:: Hoch
Story Points:: 8
Sprint:: 1
===== Akzeptanzkriterien
[source,gherkin]
....
Given ich bin eingeloggt
And mein Warenkorb enthält mindestens einen Artikel
When ich auf "Bestellen" klicke
And ich eine Lieferadresse auswähle
And ich eine Zahlungsart auswähle
And ich die Bestellung bestätige
Then wird eine Bestellung mit Status "offen" erzeugt
And ich erhalte eine Bestätigungs-E-Mail
And mein Warenkorb ist geleert
....
===== Geschäftsregeln
* <<BR-001>>: Mindestbestellwert 10 EUR
* <<BR-003>>: Maximal 99 Stück pro Position
===== Tasks
* [ ] REST-Endpoint POST /api/bestellungen
* [ ] BestellungService implementieren
* [ ] E-Mail-Versand (async)
* [ ] Unit Tests
* [ ] Integration Tests
==== US-002: Bestellstatus einsehen
[horizontal]
Story:: Als *Kunde* möchte ich *den Status meiner Bestellungen sehen*,
damit *ich weiß, wann meine Lieferung ankommt*.
Priorität:: Mittel
Story Points:: 3
Sprint:: 1
===== Akzeptanzkriterien
[source,gherkin]
....
Given ich bin eingeloggt
And ich habe mindestens eine Bestellung
When ich meine Bestellübersicht öffne
Then sehe ich alle meine Bestellungen mit aktuellem Status
And die Bestellungen sind nach Datum sortiert (neueste zuerst)
....
=== Epic: Bestellverwaltung
==== US-010: Bestellung stornieren
[horizontal]
Story:: Als *Sachbearbeiter* möchte ich *eine Bestellung stornieren können*,
damit *ich auf Kundenwünsche reagieren kann*.
Priorität:: Mittel
Story Points:: 5
Sprint:: 2
// Weitere User Stories...
== Geschäftsregeln
[[BR-001]]
=== BR-001: Mindestbestellwert
Der Mindestbestellwert beträgt 10,00 EUR.
[[BR-003]]
=== BR-003: Maximale Artikelmenge
Pro Position können maximal 99 Stück bestellt werden.
== Fachliches Datenmodell
[plantuml]
....
@startuml
entity Bestellung {
nummer: Bestellnummer
datum: Datum
status: Bestellstatus
gesamtbetrag: Geldbetrag
}
entity Bestellposition {
menge: Anzahl
einzelpreis: Geldbetrag
}
entity Kunde {
kundennummer: Kundennummer
name: Personenname
}
Kunde ||--|{ Bestellung
Bestellung ||--|{ Bestellposition
@enduml
....
== Sprint-Planung
=== Sprint 1
* US-001: Bestellung aufgeben (8 SP)
* US-002: Bestellstatus einsehen (3 SP)
* Velocity: 11 SP
=== Sprint 2
* US-010: Bestellung stornieren (5 SP)
* ...Alternative: Use-Case-Spezifikation (klassisch)
Für Projekte, die eine klassische Use-Case-Dokumentation bevorzugen:
== Anwendungsfälle
=== UC-001: Bestellung aufgeben
[horizontal]
Akteur:: Kunde
Vorbedingung:: Warenkorb enthält mindestens einen Artikel
Auslöser:: Kunde klickt "Bestellen"
==== Ablauf
1. System zeigt Bestellübersicht
2. Kunde wählt Lieferadresse
3. Kunde wählt Zahlungsart
4. Kunde bestätigt Bestellung
5. System prüft Geschäftsregeln (BR-001, BR-003)
6. System erzeugt Bestellung mit Status "offen"
7. System sendet Bestätigungs-E-Mail
==== Alternativabläufe
*4a. Mindestbestellwert nicht erreicht:*
4a1. System zeigt Fehlermeldung
4a2. Zurück zu Schritt 1
*5a. Zahlungsautorisierung fehlgeschlagen:*
5a1. System zeigt Zahlungsfehler
5a2. Zurück zu Schritt 3
==== Nachbedingung
* Bestellung existiert mit Status "offen"
* Warenkorb ist geleert
* Bestätigungs-E-Mail wurde versendet
==== Geschäftsregeln
* <<BR-001>>
* <<BR-003>>
==== Activity Diagram
[plantuml]
....
@startuml
start
:Bestellübersicht anzeigen;
:Lieferadresse auswählen;
:Zahlungsart auswählen;
:Bestellung bestätigen;
if (Mindestbestellwert erreicht?) then (ja)
if (Zahlungsautorisierung OK?) then (ja)
:Bestellung erzeugen;
:Status = "offen";
fork
:Warenkorb leeren;
fork again
:Bestätigungs-E-Mail senden;
end fork
:Bestellbestätigung anzeigen;
else (nein)
:Zahlungsfehler anzeigen;
stop
endif
else (nein)
:Fehlermeldung anzeigen;
stop
endif
stop
@enduml
....| User Stories eignen sich besser für iterative Entwicklung mit Scrum. Use Cases sind nützlich für komplexe Abläufe mit vielen Alternativpfaden oder wenn eine formale Dokumentation gefordert ist. |
3.4. Schritt 4: AGENTS.adoc generieren lassen
Erstelle basierend auf specs/fsd.adoc und unseren technischen
Rahmenbedingungen eine technische Spezifikation als agents.adoc
im Projektstamm.
Diese Datei dient als Anweisung für dich (Claude Code) bei der
Implementierung. Enthalten sein soll:
- Technologie-Stack mit Versionen
- Architekturprinzipien und Package-Struktur
- Coding-Konventionen
- Mapping von FSD-Elementen zu Code-Artefakten
- Test-Strategie
- Workflow-Anweisungen für die Implementierung
Wichtig: Die fsd.adoc bleibt die Single Source of Truth für
fachliche Anforderungen.3.4.1. Erwartete Struktur der agents.adoc
= Technische Spezifikation: [Projektname]
:revdate: 2026-03-19
== Fachliche Spezifikation
IMPORTANT: Die fachlichen Anforderungen sind in `specs/fsd.adoc` definiert.
Diese Datei ist die Single Source of Truth für das WAS.
== Technologie-Stack
[cols="1,2"]
|===
| Komponente | Version/Details
| Java | 25 (LTS)
| Build | Maven 3.9.x
| Framework | Quarkus 3.x
| Datenbank | PostgreSQL 18
| ORM | Hibernate ORM mit Panache
| Migration | Flyway
| API-Docs | SmallRye OpenAPI
| JSON | Jackson
|===
== Architektur
=== Layer-Architektur
....
src/main/java/at/htl/projekt/
├── entity/ # JPA Entities
│ ├── Bestellung.java
│ └── Bestellposition.java
├── repository/ # Data Access (Panache)
│ └── BestellungRepository.java
├── service/ # Business Logic
│ └── BestellungService.java
├── boundary/ # REST Resources
│ └── BestellungResource.java
└── dto/ # Data Transfer Objects
├── BestellungDTO.java
└── CreateBestellungDTO.java
....
=== Schichten-Regeln
[IMPORTANT]
====
* `boundary/` → ruft `service/` auf
* `service/` → ruft `repository/` auf, enthält Geschäftslogik
* `repository/` → Datenzugriff via Panache
* `entity/` → JPA-Entities mit Validierung
* `dto/` → Für REST-Schnittstellen, keine Entities nach außen
====
== Coding-Konventionen
=== Allgemein
* Package-Prefix: `at.htl.projekt`
* Keine Wildcards in Imports
* Records für DTOs
* Optional statt null-Returns
=== Naming
* Klassen: PascalCase
* Methoden/Variablen: camelCase
* Konstanten: SCREAMING_SNAKE_CASE
* Packages: lowercase
* REST-Resources: `*Resource.java`
* Services: `*Service.java`
* Repositories: `*Repository.java`
=== Quarkus-spezifisch
* CDI für Dependency Injection (`@Inject`, `@ApplicationScoped`)
* Panache Active Record oder Repository Pattern
* `@Transactional` auf Service-Methoden
* `application.properties` für Konfiguration
== Mapping: FSD → Code
[cols="1,2,2"]
|===
| FSD-Element | Code-Artefakt | Beispiel
| Glossar-Begriff
| Entity in `entity/`
| `Bestellung.java`
| User Story
| Service-Methode + REST-Endpoint
| `BestellungService.aufgeben()`
| Geschäftsregel
| Validierung in Entity oder Service
| `Bestellung.validiereMindestwert()`
| Akteur
| Security Role
| `@RolesAllowed("kunde")`
|===
== Test-Strategie
[cols="1,2,2"]
|===
| Ebene | Scope | Technologie
| Unit Tests
| Services, Entities
| JUnit 5, AssertJ, Mockito
| Integration Tests
| Repository, REST
| @QuarkusTest, Testcontainers
| API Tests
| REST-Endpoints
| REST Assured
| Acceptance Tests
| User Stories End-to-End
| Cucumber (optional)
|===
== Workflow für Claude Code
=== Bei neuen User Stories
1. `specs/fsd.adoc` konsultieren
2. Relevante User Story identifizieren
3. Entity erstellen/erweitern (falls nötig)
4. Repository erstellen/erweitern
5. Service-Methode implementieren
6. REST-Resource implementieren
7. Tests auf allen Ebenen
=== Regeln
* Bei Unklarheiten: *nachfragen*, nicht raten
* Fachbegriffe exakt aus Glossar übernehmen
* Keine Änderungen an der Fachlichkeit ohne Rücksprache
* Commits nach jeder logischen Einheit
== Prompts für häufige Aufgaben
=== Neue User Story implementieren
[source]
....
Implementiere US-XXX aus specs/fsd.adoc.
Erstelle Entity, Repository, Service und Resource.
Schreibe Tests für jede Schicht.
....
=== Code Review anfordern
[source]
....
Prüfe [Datei/Package] auf:
- Einhaltung der Schichten-Architektur
- Clean Code und SOLID
- Vollständigkeit der Tests
- Übereinstimmung mit fsd.adoc
....3.5. Schritt 5: CLAUDE.md als Einstiegspunkt erstellen
Claude Code liest automatisch die CLAUDE.md im Projektstamm. Diese Datei dient als Einstiegspunkt und verweist auf die detaillierten .adoc-Spezifikationen:
# Projektanweisungen
## Wichtige Dateien
Lies vor jeder Aufgabe folgende Spezifikationen:
- `specs/fsd.adoc` – Fachliche Spezifikation (User Stories, Glossar, Regeln)
- `agents.adoc` – Technische Vorgaben (Stack, Architektur, Konventionen)
- `specs/chats.adoc` – Bisherige Entscheidungen und Kontext
## Regeln
- Fachbegriffe exakt aus dem Glossar in fsd.adoc verwenden
- Bei Unklarheiten: **nachfragen**, nicht raten
- Dokumentation in AsciiDoc (.adoc) erstellen
- Commits nach jeder logischen Einheit
## Technologie-Stack
- Java 25, Quarkus 3.x, PostgreSQL 18
- Maven als Build-Tool
- Layer-Architektur (entity → repository → service → boundary)
## Schnellstart
```bash
# Projekt bauen
./mvnw clean compile
# Tests ausführen
./mvnw test
# Dev-Modus starten
./mvnw quarkus:dev
```|
Warum CLAUDE.md zusätzlich zu agents.adoc?
|
3.6. Schritt 6: Implementierung starten
Mit den generierten Spezifikationen kann die Implementierung beginnen:
# Claude Code starten
claude
# Initialisierung
/init
Verwende den Plan Mode (/plan) für komplexe Implementierungen – Claude zeigt dann zuerst einen Umsetzungsplan zur Bestätigung. Siehe Plan Mode in den Best Practices.
|
3.6.1. Beispiel-Prompts für die Implementierung
Lies agents.adoc und specs/fsd.adoc.
Erstelle die Grundstruktur des Projekts gemäß der
definierten Package-Struktur./plan Implementiere US-001 (Bestellung aufgeben) aus specs/fsd.adoc.
Befolge die Architekturprinzipien aus agents.adoc.
Beginne mit der Entity und arbeite dich nach außen vor./plan Erstelle Tests für US-001 basierend auf den Akzeptanzkriterien
in specs/fsd.adoc. Jedes Given/When/Then soll ein Testfall sein.|
Akzeptanzkriterien als Testgrundlage Die Akzeptanzkriterien in der FSD (Gherkin-Format: Given/When/Then) sind die ideale Vorlage für Tests:
So stellst du sicher, dass die Tests genau das prüfen, was fachlich gefordert ist. |
4. Best Practices
4.1. Modellauswahl
Die Wahl des Backend-Modells beeinflusst die Ergebnisqualität erheblich. Die meisten KI-Coding-Tools erlauben den Wechsel über /model oder in den Einstellungen.
|
Leistungsfähigere Modelle liefern bessere Ergebnisse bei:
Empfehlung: Für agentisches Programmieren die jeweils stärksten verfügbaren Modelle verwenden (z.B. Claude Opus, GPT-4, Gemini Ultra). |
| Anbieter | Top-Modell | Stärken |
|---|---|---|
Anthropic |
Claude Opus |
Reasoning, lange Kontexte, Code-Qualität |
OpenAI |
GPT-4 |
Breites Wissen, Tool-Integration |
Gemini Ultra |
Multimodal, schnelle Iteration |
|
Mistral |
Mistral Large |
Open-Source-nah, selbst hostbar |
| Bei Budget-Einschränkungen: Für einfache Tasks (Formatierung, kleine Fixes) reichen kleinere Modelle. Für Architektur und komplexe Features das beste verfügbare Modell wählen. |
4.2. Sprache beim Prompten
Ein verbreiteter Mythos: Englische Prompts sparen Tokens. Die Ersparnis ist jedoch minimal und lohnt sich praktisch nicht.
| Komponente | Beispiel | Anteil |
|---|---|---|
Dein Prompt |
20-50 Tokens |
< 1% |
Gelesene Dateien |
10.000-30.000 Tokens |
~50% |
Claudes Antwort + Code |
10.000-30.000 Tokens |
~50% |
Die Sprache des Prompts beeinflusst den Gesamtverbrauch kaum – der Code und Kontext dominieren.
|
Schreibe in der Sprache, in der du am präzisesten formulieren kannst.
|
| Für Projekte mit deutschsprachiger Fachlichkeit (Glossar, User Stories, Team) ist Deutsch die bessere Wahl. Die KI versteht beide Sprachen gleich gut. |
4.3. Plan Mode
Der Plan Mode ergänzt unseren Workflow auf Task-Ebene: Bevor Claude Code ausführt, zeigt er einen Umsetzungsplan und wartet auf Bestätigung.
4.3.1. Aktivierung
# Beim Start
claude --plan "Implementiere US-001"
# Oder interaktiv
/plan Implementiere US-001 aus specs/fsd.adoc4.3.2. Vorteile
| Ohne Plan Mode | Mit Plan Mode |
|---|---|
Claude legt sofort los |
Claude zeigt erst den Plan |
Fehler fallen spät auf |
Fehler werden früh erkannt |
Schwer zu korrigieren |
Einfach anzupassen vor Umsetzung |
Mehr Tokens bei Korrekturen |
Weniger Iterationen |
4.3.3. Zusammenspiel mit unserem Workflow
| Ebene | Planungsmethode |
|---|---|
Projekt |
Unser Workflow (Story → FSD → Agents) |
Task |
Plan Mode ( |
Unser Workflow trennt Planung von Implementierung auf Projektebene. Der Plan Mode macht dasselbe für einzelne Tasks – beides zusammen ergibt maximale Kontrolle.
Besonders bei komplexen User Stories oder Refactorings /plan verwenden. Bei einfachen Fixes (Typos, kleine Änderungen) ist der Plan Mode optional.
|
4.4. Kontext-Management
Das wichtigste Ressource in Claude Code ist das Kontext-Fenster. Es füllt sich schnell mit Dateiinhalten und Command-Outputs.
|
Kontextfüllung anzeigen und überwachen
Mit /context siehst du die aktuelle Kontextnutzung:
/contextAusgabe:
Context usage: 45,231 / 128,000 tokens (35%)Übersicht der relevanten Befehle:
| Befehl | Funktion |
|---|---|
|
Zeigt aktuelle Nutzung |
|
Zeigt Plan-Limits und Verbrauch |
|
Komprimiert den Kontext |
|
Löscht den Kontext komplett |
Permanente Statuszeile einrichten:
In /config oder in ~/.claude/settings.json:
{
"statusLine": "context"
}Dann siehst du die Kontextfüllung dauerhaft am unteren Bildschirmrand.
Faustregel:
-
< 50%: Weiterarbeiten
-
~50%:
/compactausführen (Claude fasst bisherigen Kontext zusammen) -
> 70%: Dringend komprimieren, Performance leidet
-
Neue Aufgabe:
/clearund frisch starten
4.5. Thinking-Modi
Claude Code unterstützt verschiedene Denk-Intensitäten:
| Keyword | Verwendung |
|---|---|
|
Standard-Überlegung |
|
Komplexere Probleme |
|
Architektur-Entscheidungen |
|
Maximale Analyse (z.B. Security-Review) |
Ultrathink: Analysiere die Sicherheit unserer
Authentifizierungs-Implementierung.4.6. Subagents für spezialisierte Aufgaben
Für komplexe Reviews können dedizierte Subagents definiert werden:
.claude/agents/security-reviewer.md---
name: security-reviewer
description: Reviews code for security vulnerabilities
tools: Read, Grep, Glob, Bash
model: opus
---
Du bist ein Senior Security Engineer. Prüfe Code auf:
- Injection-Schwachstellen (SQL, XSS, Command Injection)
- Authentifizierungs- und Autorisierungsfehler
- Secrets oder Credentials im Code
- Unsichere Datenverarbeitung
Gib konkrete Zeilenreferenzen an.4.7. Chat-Protokollierung mit chats.adoc
Alle Prompts werden in chats.adoc protokolliert, bevor sie nach Claude Code kopiert werden. Vorteile:
| Vorteil | Beschreibung |
|---|---|
Reproduzierbar |
Kontext kann jederzeit neu aufgebaut werden |
Dokumentation |
Entscheidungen sind nachvollziehbar |
Lerneffekt |
Gute Prompts können wiederverwendet werden |
Teamfähig |
Kollegen sehen, wie das Projekt entstanden ist |
4.7.1. Workflow
-
Prompt in
chats.adocschreiben -
Prompt nach Claude Code kopieren
-
Weiterarbeiten – Claudes Antworten müssen nicht protokolliert werden
4.7.2. Wichtig: Selbsterklärende Prompts
Bei Antworten auf Claudes Fragen immer den Kontext wiederholen. Nach /compact oder beim Neuaufbau des Kontexts fehlt sonst der Bezug.
| ❌ Schlecht | ✅ Gut |
|---|---|
Ja |
Ja, verwende das Builder Pattern für die Bestellung-Entity. |
4.7.3. Vorlage: chats.adoc
= Chat-Protokoll: [Projektname]
== Session 1
Lies specs/story.adoc und stelle mir Fragen zur Klärung
der fachlichen Anforderungen.
'''
Ja, es gibt drei Rollen: Kunde, Sachbearbeiter, Admin
'''
Ja, verwende das Builder Pattern für die Bestellung-Entity
'''
Nein, kein Event Sourcing – klassisches CRUD reicht
'''
Erstelle basierend auf unserer Diskussion eine vollständige
fachliche Spezifikation als specs/fsd.adoc.
== Session 2
Implementiere US-001 aus specs/fsd.adoc.
Erstelle Entity, Repository, Service und Resource.
Schreibe Tests für jede Schicht.
'''
Nein, die Validierung soll im Service erfolgen, nicht in der Entity.
Claudes Antworten werden nicht protokolliert – sie können bei Bedarf aus der Claude Code Session-History (/history) rekonstruiert werden.
|
4.8. Dateien trennen statt verschmelzen
| Datei | Zweck | Änderungshäufigkeit |
|---|---|---|
|
Einstiegspunkt für Claude Code |
Selten (nur bei Strukturänderungen) |
|
Ursprüngliche Vision |
Einmalig |
|
Fachliche Wahrheit |
Bei Scope-Änderungen |
|
Prompt-Protokoll und Entscheidungen |
Jede Session |
|
Technische Anweisungen (Details) |
Bei Tech-Entscheidungen |
|
Agents, Commands, Hooks |
Bei Workflow-Optimierung |
5. Anhang
5.1. Verzeichnisstruktur (Komplett)
mein-projekt/
├── CLAUDE.md # Einstiegspunkt für Claude Code
├── agents.adoc # Technische Spec (Details)
├── specs/
│ ├── story.adoc # Ursprüngliche Vision
│ ├── fsd.adoc # Fachliche Spezifikation
│ └── chats.adoc # Prompt-Protokoll
├── .claude/
│ ├── agents/ # Spezialisierte Subagents
│ ├── commands/ # Eigene Slash-Commands
│ └── settings.json # Projekteinstellungen
├── src/
│ ├── main/
│ │ ├── java/at/htl/projekt/
│ │ │ ├── entity/ # JPA Entities
│ │ │ ├── repository/ # Panache Repositories
│ │ │ ├── service/ # Business Logic
│ │ │ ├── boundary/ # REST Resources
│ │ │ └── dto/ # Data Transfer Objects
│ │ └── resources/
│ │ └── application.properties
│ └── test/
│ └── java/at/htl/projekt/
├── docs/
│ ├── architecture.adoc # Architektur-Entscheidungen
│ └── api.adoc # API-Dokumentation
├── pom.xml # Maven Build
└── README.adoc5.2. Nützliche Claude Code Befehle
| Befehl | Funktion |
|---|---|
|
Generiert initiale CLAUDE.md |
|
Komprimiert Kontext-Fenster |
|
Löscht aktuellen Kontext |
|
Öffnet Konfiguration |
|
Wechselt das Modell |
|
Zeigt Kontext-Nutzung |
|
Zeigt Plan-Limits |